Neural Networks 101: Part 6
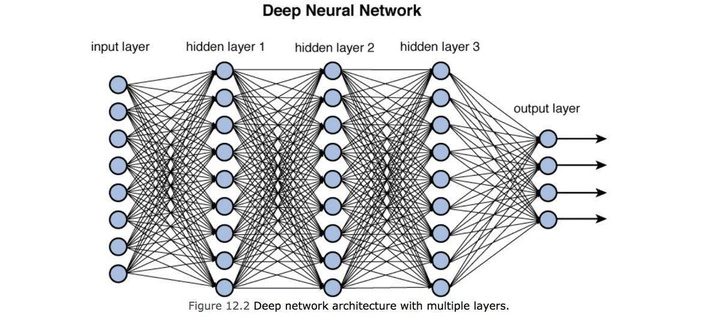
In this post, we are going to explore Transfer Learning
Transfer Learning
Transfer Learning is a technique that uses an already pretrained model and applying it to a new problem domain.
This is very useful when a problem domain has a small set of training data or when an engineer is looking for creative ways to solve a problem e.g. Using a pretrained model in away that is different from its original purpose.
As we’ve seen in previous articles, Neural Networks are made up of layers that connect via activation functions.
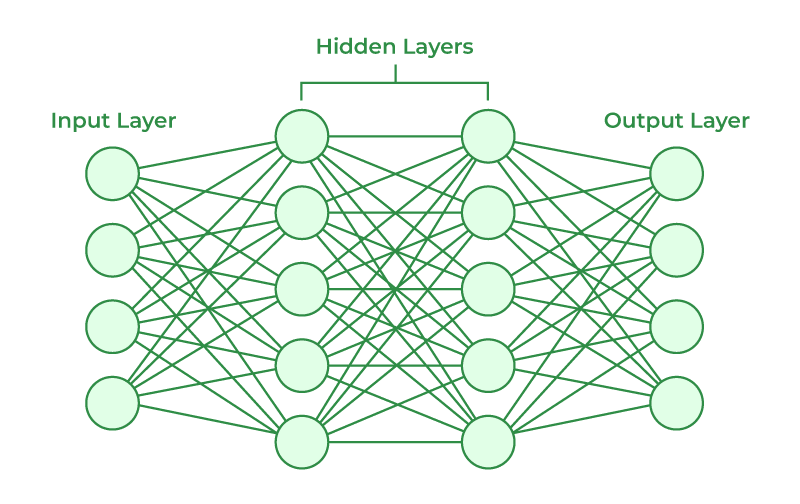
The input and output layers in the Neural Net has a certain of inputs that usually reflect the labels of the domain.
The final output of of the Neural Net corresponds to the labels of a domain e.g. the final output for classification.
When we perform transfer learning, we are essentially replacing the final output layer, with a layer that fits a new problem domain.
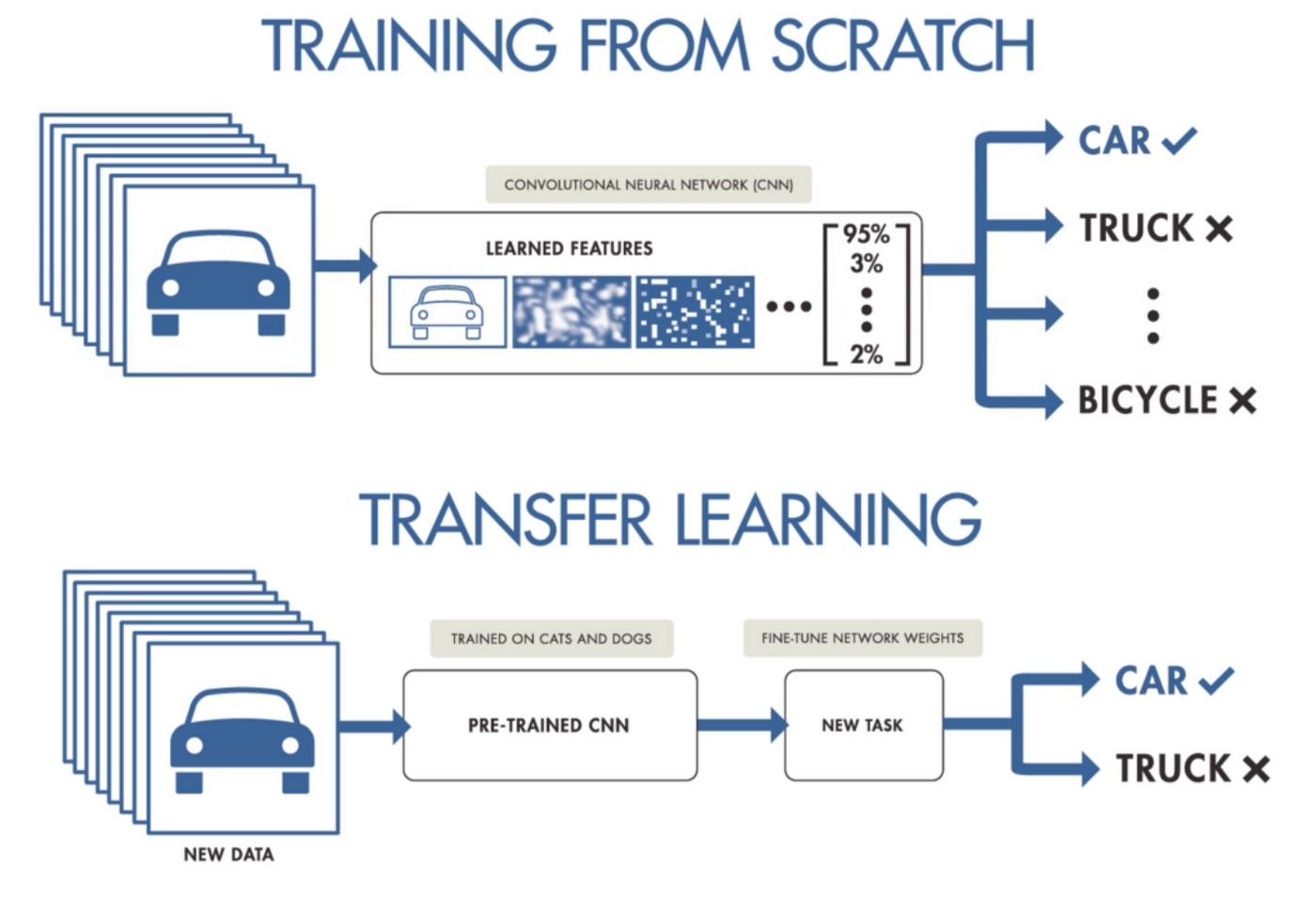
A classic example is, taking a pre-trained model e.g. ImageNet that is trained on thousands of images and performing transfer learning on a specific domain that may have only 2 outputs e.g. dog vs cat.
Below, we will go through high level steps on performing transfer learning.
Replace the output layer
In order to perform transfer learning, we would need to remove the final output layer and replace it with a new layer that will represent a dog or cat.
This new layer will consist of its own randomized parameters. The reason for having their own randomized parameters is because the previous layers have already been trained.
Their parameters have been fine-tuned to identify images, we still want to leverage that learned behaviour through their parameters.
Freeze the previous layers
When training in transfer learning, we usually freeze the previous layers, this prevents backpropagation on the parameters of the previous layers, thus, preserving the learned behaviour of the pretrained model.
The training will only adjust the parameters for the new layer (the output layer), this way we can leverage the previous layers learned behaviour.
Unfreezing the previous layers
After training the model for some iterations, the parameters of the output layer will be adjusted according to an increasing performance. After reaching a satisfactory level of performance, we unfreeze the previous layers.
This will allow our model to be fine tuned further by slightly adjusting the previous parameters to fit our problem domain further.
A very important distinction needs be made. The Learning Rate for the output layer and the pretrained layers needs to be different.
The Learning Rate for our pretrained layers needs to be smaller than the output layer.
We only want to adjust the parameters of the pretrained layers slightly since those parameters have already been pretrained.
We don’t want to loose that accuracy but we want to adjust to our problem domain.
The Learning Rate for our output layer will be larger, since its a new layer, we want it to fit to our problem domain well.
Summary
Transfer Learningis a technique to use pre-trained models in a new problem domain- It allows reusing a pretrained model in a way that is novel and with less training data for a particular domain
- This is achieved by replacing the output layer with a new layer that suits our problem domain
- The new layer and the previous layers have their own parameters
- The new layer and the previous layers have their own learning rates
- We freeze the previous layers when initially training to not adjust their parameters since we want to retain the trained behaviour of the previous layers
- The output layers’ parameters are adjusted to the problem domain
- Once the model has been trained to a good level, we unfreeze the previous layer so that we can slightly adjust their parameters to fit the problem domain better